Many SAS users have inquired about SAS Cloud Analytic Services’ (CAS) Distributed Network File System (DNFS) of late, so let’s look at it further in this blog post. (Learn more about CAS.)
The “NFS” in “DNFS”
Let’s start at the beginning. The “NFS” in DNFS stands for “Network File System” and refers to the ability to share files across a network. As the picture below illustrates, a network file system lets numerous remote hosts access another host’s files.
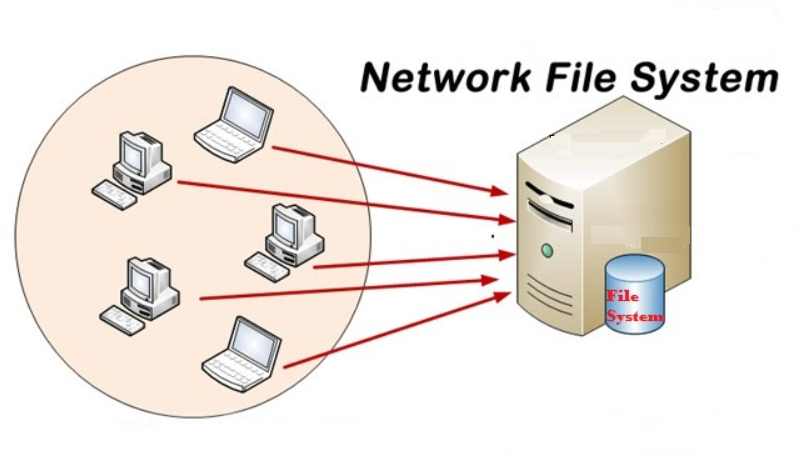
There are numerous network file system protocols that can be used for file sharing – e.g. CIFS, Ceph, Lustre – but the most common on Linux is NFS. While NFS is the dominant file-sharing protocol, the “NFS” part of the DNFS does not correspond to the NFS protocol. Currently all the DNFS supported file systems are based on NFS, but DNFS may support file systems based on other protocols in the future. So, it’s best to think of the “NFS” part of “DNFS” as a generic “network file system” (clustered file system) and not the specific NFS protocol.
The “D” in “DNFS”
The “D” in DNFS stands for “Distributed” but it does not refer to the network file system. By definition, that is already distributed since the file system is external to the machines accessing it. The “Distributed” in DNFS refers to CAS’ ability to use a network file system in a massively parallel way. With a supported file system mounted identically on each CAS node, CAS can access (both read and write) the file system’s CSV and SASHDAT files from every worker node in parallel.
This parallel file access is not an attribute of the file system, it is a capability of CAS. By definition, network file systems facilitate access at the file level, not the block level. With DNFS, CAS actively manages parallel block level I/O to the network file system, making sure file seek locations and block I/O operations do not overlap, etc.
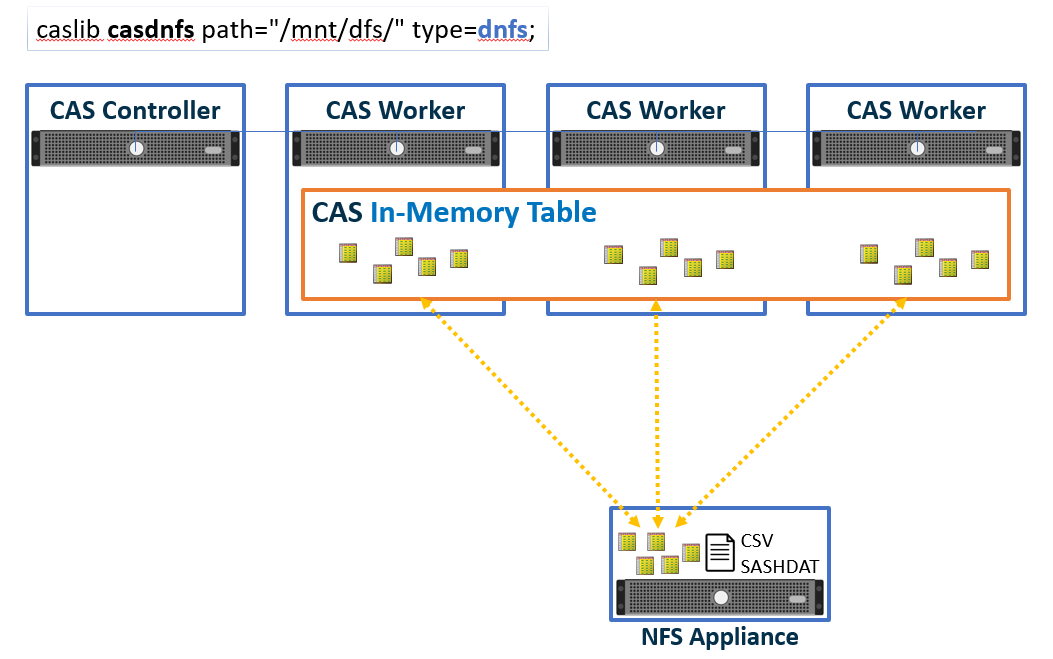
DNFS as CAS Backing Store
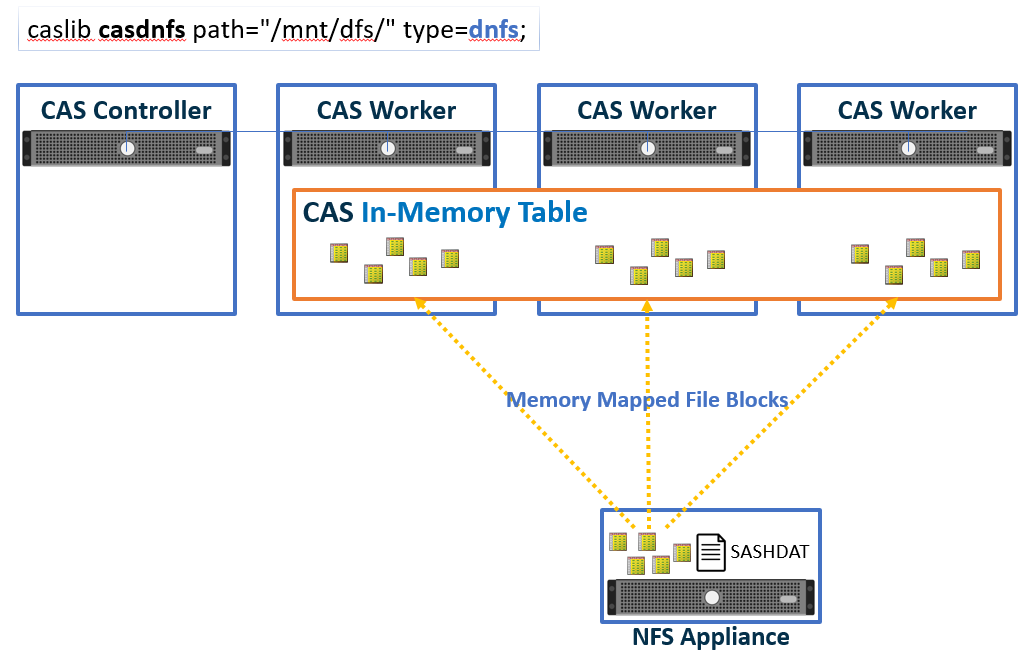
Not only can CAS perform multi-machine parallel I/O from network file systems, it can also memory-map NFS SASHDAT files directly into CAS. Thus, SASHDAT files on DNFS act as both the CASlib data source as well as the virtual memory “backing store,” often negating the need for CAS to utilize CAS_DISK_CACHE. Given this capability, any network file system used by DNFS must support memory mapping (mmap()).
Note 1: Data transformations on load, such as row filtering and field selection, as well as encryption can trigger CAS_DISK_CACHE usage. Since the data must be transformed (subset and/or decrypted), CAS copies the transformed data into CAS_DISK_CACHE to support CAS processing.
Note 2: It is possible to use DNFS atop an encrypting file system or hardware storage device. Here, the HDAT blocks are stored encrypted but transmitted to the CAS I/O layer decrypted. Assuming no other transformations, CAS_DISK_CACHE will not be used in this scenario.
Performance Considerations
DNFS-based CAS loading will only be as fast as the slowest component involved. The chosen NFS architecture (hardware and CAS connectivity) should support I/O throughput commensurate with the CAS installation and in-line with the implementation’s service level agreements. So, while DNFS supports NFS-mounted directories from standard Unix/Linux file systems, for large implementations, you’ll probably want to pair CAS with a sophisticated file system technology. Vendors like MapR, NetApp, and EMC offer file systems and appliances that provide performance as well as fault tolerance using multi-machine architectures. To illustrate one example, consider the following diagram. It assumes the NetApp ONTAP clustering architecture. A different file system technology might look a little different but the same basic ideas will apply.
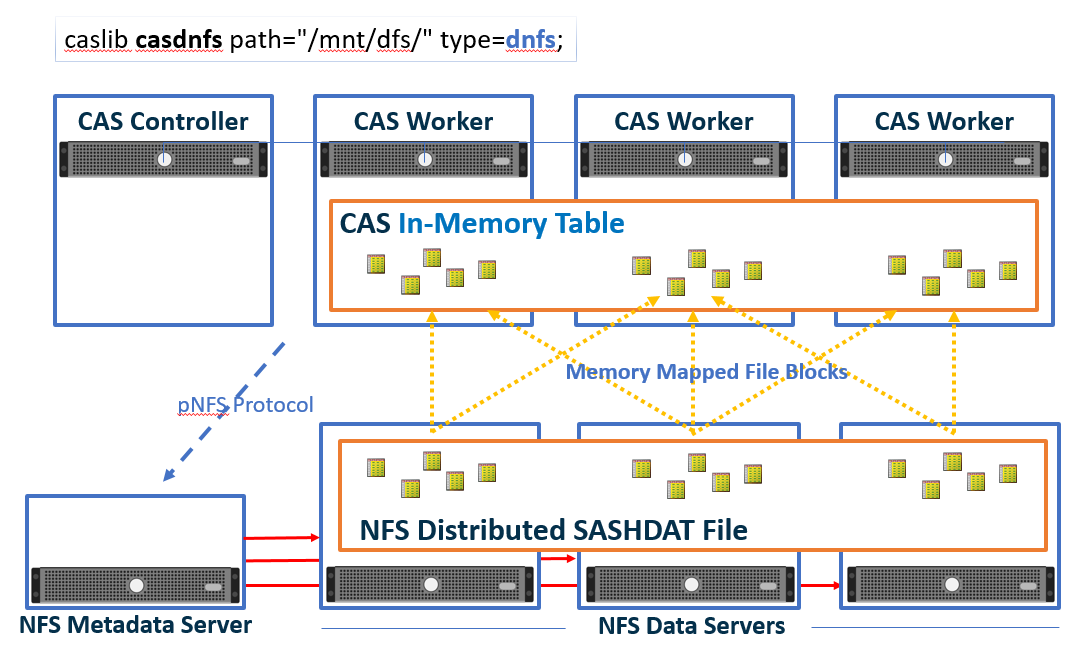
As described earlier, CAS manages the parallel I/O operations. Requests from CAS are sent to the appliance and handled by the NFS metadata server. The storage device implementing the NFS protocol points CAS DNFS to the proper file and block locations on the NFS data servers which pass the data to the CAS worker nodes directly.
